Data sufficiency
Source:vignettes/articles/art-020-data-sufficiency.Rmd
art-020-data-sufficiency.RmdThe time span (or range) of MIDFIELD data varies by institution. At the upper and lower limits of a data range, a potential for false counts exists when a metric (such as graduation rate) requires knowledge of timely degree completion. For such metrics, student records that produce problematic results due to insufficient data are nearly always excluded from study.
This article in the MIDFIELD workflow:
- Planning
- Initial processing
- Data sufficiency
- Degree seeking
- Identify programs
- Blocs
- Groupings
- Metrics
- Displays
Definitions
- data range
-
The overall span of academic terms of student unit record data provided by an institution. We are particularly interested in the lower and upper limits of a continuous range.
- timely completion term
-
The last term in which a student’s degree completion would be considered timely. In many cases the timely completion (TC) term is 6 years after admission. The TC term can be adjusted to account for transfer credits. (Currently, there is no mechanism for extending the TC term for co-ops or migrators.)
- data sufficiency criterion
-
Student records are limited to those for which available data are sufficient to assess timely completion without biased counts of completers or non-completers.
Upper-limit data sufficiency
For students admitted too near the upper limit of their institution’s data range, the available data cover an insufficient number of years to know if completion is timely. To illustrate, in the figure we compare two students admitted in different terms with representative time spans shown for timely completion. In this scenario, we assume institution data is available from 1986 to 1996.
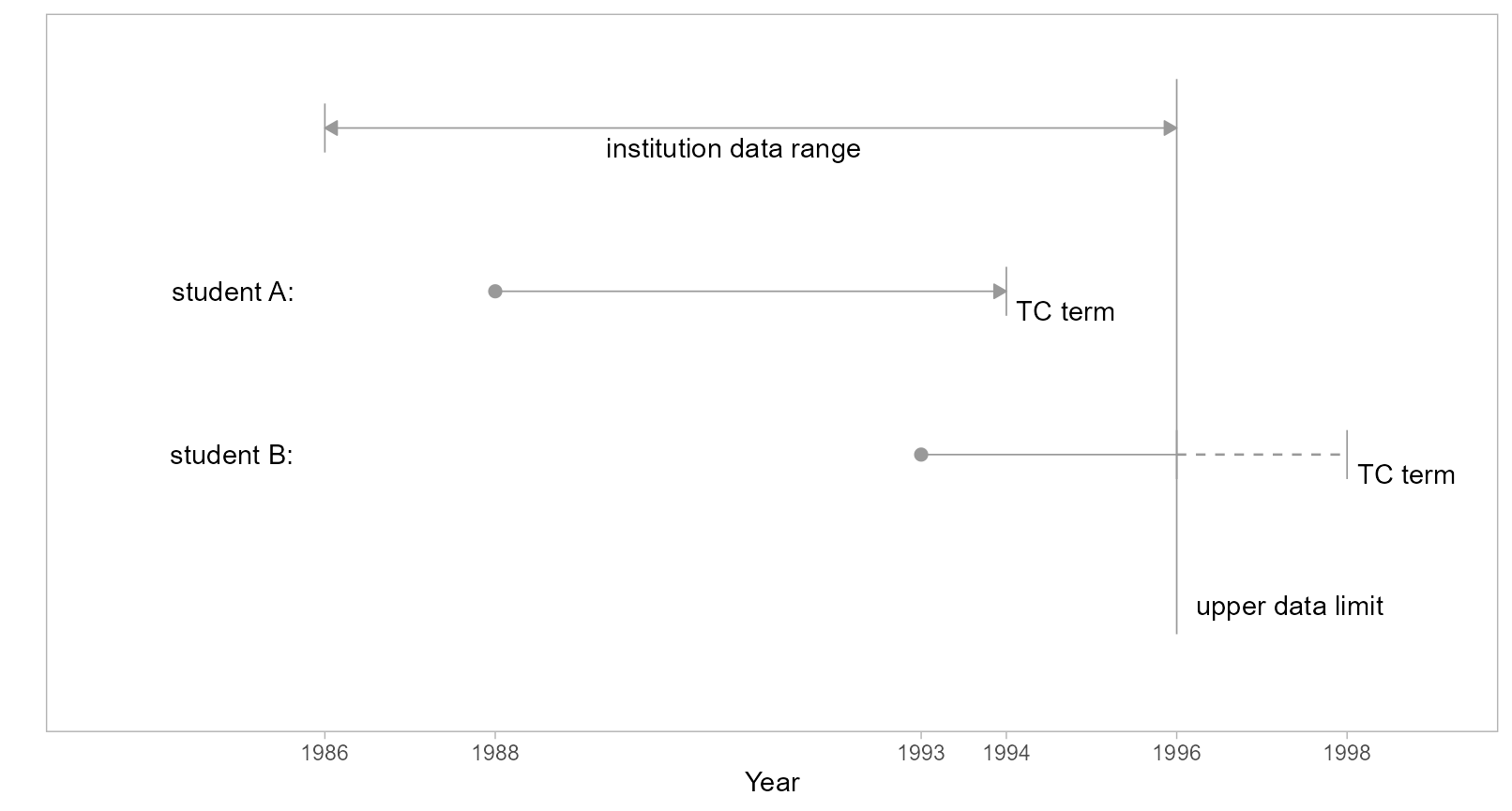
Figure 1: Upper limit data sufficiency.
- Student A
-
Student A enters in 1988 with a timely completion (TC) term in 1994. In both of the following cases, the data sufficiency criterion is satisfied and the records are included in a study.
A-1: First time in college (FTIC), so we know their first term is their entry term (i.e., they are not a continuing student) and we can determine their TC term.
A-2: Transfer student, and we know their first term in a MIDFIELD institution. We have no knowledge of how much time was spent accumulating their pre-MIDFIELD credit hours, but we can estimate a TC term with respect to their “level” at entry, that is, entering as a first-year student, second-year student, etc.
- Student B
-
Student B enters in 1993 with a TC term in 1998, two years beyond the range of the data. We have several possible cases,
B-1: Before the data limit, the student completes their program (timely completion, known record)
B-2: Before the data limit, the student leaves the data base (non-completion, known record)
B-3: After the data limit, the student completes before their TC term (timely completion, no record)
B-4: After the data limit, the student completes after their TC term or fails to complete (late completion or non-completion, no record)
Because the outcomes in cases B-3 and B-4 are not in the record, to include case B-1 and B-2 invariably produces a miscount of timely completers, late completers, and non-completers. Thus all student B records are excluded from the study.
Lower-limit data sufficiency
To determine data sufficiency record exclusions at the lower limit of the data range, we compare a student’s first term (non-summer) to the first term of the data range (also non-summer). When these two terms are identical, the complete unit record is excluded. We illustrate with the three scenarios described below.
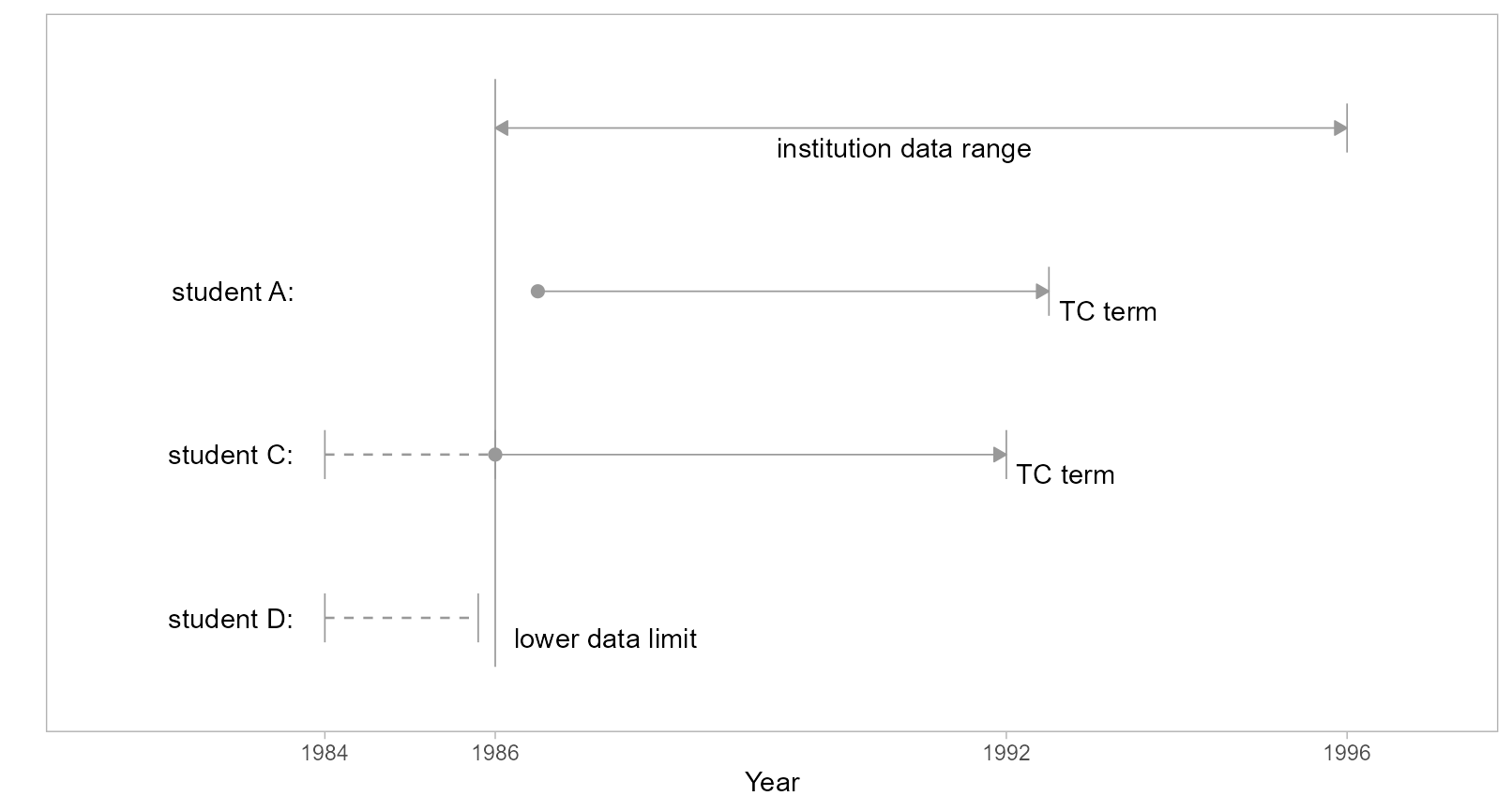
Figure 2: Lower limit data sufficiency.
- Student A
-
Like Student A in Figure 1, they enter the dataset in a term following the data lower limit and are included in a study.
- Student C
-
Student C enters the institution before the lower limit of the data range (a “continuing” student) or they enter the institution at the lower limit precisely.
C-1: If student C is continuing, regardless of status (FTIC or transfer), making an estimate of their TC term invariably leads to false counts because we have no knowledge of how much time was spent accumulating credit hours at their MIDFIELD institution before the lower data limit. Including C-1 would also produce false counts because of student D (discussed below).
C-2: If student C is not continuing, that is, their first time entry to a MIDFIELD institution is at the lower data limit (here, 1986), we would include them in a study if we could. Unfortunately, we cannot distinguish them from continuing students. Having to exclude C-1 inherently excludes C-2 as well.
- Student D
-
Student D enters the institution at the same time as continuing student C but leaves the database before the data lower limit term.
D-1: Student D did not timely-complete their program. In this case, if we include student C our count of non-completers is low (D-1 cases are missing), resulting in an inflated ratio of completers to non-completers.
D-2: Student D did timely-complete their program. Here, if we include student C our count of completers is low (D-2 cases are missing), resulting in a diminished ratio of completers to non-completers.
The balance of these two effects is unknowable. Since student D cannot possibly be included, Student C must also be excluded.
Method
Specific student unit records at the upper and lower limits of an institution’s data range must be excluded to prevent false counts due to insufficient data. Based on the discussion above, two specific filters are implemented:
Lower limit. All IDs extant in the non-summer lower limit of an institution’s data range are labeled for possible exclusion.
Upper limit. All IDs for which the timely completion term exceeds the upper limit of the institution’s data range are labeled for possible exclusion.
Reminder. midfielddata is for practice, not research.
Load data
Start. If you are writing your own script to follow along, we use these packages in this article:
Load. Practice datasets. View data dictionary via
?term.
# Load data
data(term)Initial processing
Select (optional). Reduce the number of columns. Code reproduced from Getting started.
# Copy of source files with all variables
source_term <- copy(term)
# Select variables required by midfieldr functions
term <- select_basic_cols(source_term)Initialize. Assign a working data frame.
# Working data frame
DT <- copy(term)
DT
#> mcid term cip6 institution level
#> <char> <char> <char> <char> <char>
#> 1: MCID3111142225 19881 140901 Institution B 01 First-year
#> 2: MCID3111142283 19881 240102 Institution J 01 First-year
#> 3: MCID3111142283 19883 240102 Institution J 01 First-year
#> ---
#> 639913: MCID3112898894 20181 451001 Institution B 01 First-year
#> 639914: MCID3112898895 20181 302001 Institution B 01 First-year
#> 639915: MCID3112898940 20181 050103 Institution B 01 First-yearSelect. The ID column is required. The institution column is not, but is convenient when taking a closer look at the results.
# Retain the minimum number of columns
DT <- DT[, .(mcid, institution)]Filter. Retain unique IDs.
# Filter for unique IDs
DT <- unique(DT)
DT
#> mcid institution
#> <char> <char>
#> 1: MCID3111142225 Institution B
#> 2: MCID3111142283 Institution J
#> 3: MCID3111142290 Institution J
#> ---
#> 97553: MCID3112898894 Institution B
#> 97554: MCID3112898895 Institution B
#> 97555: MCID3112898940 Institution B
timely_term()
Add a column to a data frame of student-level data that indicates the latest term by which degree completion would be considered timely for every student.
Arguments.
dframeData frame of student-level records keyed by student ID. Required variable (column) ismcid.midfield_tableData frame of student-level term observations keyed by student ID. Default isterm. Required variables (columns) aremcid,term, andlevel.spanOptional integer scalar, number of years to define timely completion. Commonly used values are are 100%, 150%, and 200% ofsched_span. Default 6 years. Argument to be used by name.sched_spanOptional integer scalar, the number of years an institution officially schedules for completing a program. Default 4 years. Argument to be used by name.
Equivalent usage. The following implementations yield identical results,
# Required arguments in order and explicitly named
x <- timely_term(dframe = DT, midfield_table = term)
# Required arguments in order, but not named
y <- timely_term(DT, term)
# Using the implicit default for the midfield_table argument
z <- timely_term(DT)
# Demonstrate equivalence
check_equiv_frames(x, y)
#> [1] TRUE
check_equiv_frames(x, z)
#> [1] TRUEOutput. Adds the following columns to the data frame.
term_iStudent initial term, encoded YYYYT.level_iStudent level (01 Freshman, 02 Sophomore, etc.) in their initial term.adj_spanInteger span of years for timely completion, adjusted for a student’s initial leveltimely_termLatest term by which degree completion would be considered timely. Encoded YYYYT.
# Add timely term column and supporting variables
DT <- timely_term(DT, term)
DT
#> mcid term_i level_i adj_span timely_term
#> <char> <char> <char> <num> <char>
#> 1: MCID3111142225 19881 01 First-year 6 19933
#> 2: MCID3111142283 19881 01 First-year 6 19933
#> 3: MCID3111142290 19881 01 First-year 6 19933
#> ---
#> 97553: MCID3112898894 20181 01 First-year 6 20233
#> 97554: MCID3112898895 20181 01 First-year 6 20233
#> 97555: MCID3112898940 20181 01 First-year 6 20233Closer look
Examining the records of selected students in detail.
Example 1. The student’s initial term is Fall 2007
(encoded 20071) and their initial level is
01 First-year. The number of years to timely completion is
6 years, that is, academic years 2007–08, 08–09, 09–10, 10–11, 11–12,
12–13. Thus their timely completion term is Spring 2013 (encoded
20123).
# Display one student by ID
DT[mcid == "MCID3112785480"]
#> mcid term_i level_i adj_span timely_term
#> <char> <char> <char> <num> <char>
#> 1: MCID3112785480 20071 01 First-year 6 20123Example 2. The student’s initial term is Spring 2002
(encoded 20013) and their initial level is
03 Third-year from which we infer they have completed two
years of their program, yielding an adjusted span of 4 years. Those four
years would encompass terms 20013–20021,
20023–20031,
20033–20041, and
20043–20051, yielding a timely completion term
of Fall 2005.
# Display one student by ID
DT[mcid == "MCID3111860641"]
#> mcid term_i level_i adj_span timely_term
#> <char> <char> <char> <num> <char>
#> 1: MCID3111860641 20013 03 Third-year 4 20051Alternate source names
Arguments of midfieldr functions accept alternate names, should the
source-data file names in your workspace be named something other than
student, term, etc. For example, if we were
working with the “toy” (exercise) data sets included with midfieldr, we
might write something like this,
# A toy set of IDs
toy_mcid <- toy_student[, .(mcid)]
# Source data table names that differ from the defaults
toy_DT <- timely_term(dframe = toy_mcid, midfield_table = toy_term)
# Equivalently
toy_DT <- timely_term(toy_mcid, toy_term)
toy_DT
#> mcid term_i level_i adj_span timely_term
#> <char> <char> <char> <num> <char>
#> 1: MCID3111142897 19881 01 First-year 6 19933
#> 2: MCID3111157634 19881 01 First-year 6 19933
#> 3: MCID3111158724 19881 01 First-year 6 19933
#> ---
#> 349: MCID3112868072 20171 01 First-year 6 20223
#> 350: MCID3112869843 20173 01 First-year 6 20231
#> 351: MCID3112885339 20181 01 First-year 6 20233Silent overwriting
Existing columns with the same names as one of the added columns are
deleted and replaced. Using the toy data to illustrate, we drop the
columns added by timely term except adj_span.
# Drop three columns
toy_DT <- toy_DT[, c("term_i", "level_i", "timely_term") := NULL]
toy_DTReapplying the function, the adj_span column is silently
deleted and replaced.
# Demonstrate overwriting
toy_DT <- timely_term(toy_DT, toy_term)
toy_DT
#> mcid term_i level_i adj_span timely_term
#> <char> <char> <char> <num> <char>
#> 1: MCID3111142897 19881 01 First-year 6 19933
#> 2: MCID3111157634 19881 01 First-year 6 19933
#> 3: MCID3111158724 19881 01 First-year 6 19933
#> ---
#> 349: MCID3112868072 20171 01 First-year 6 20223
#> 350: MCID3112869843 20173 01 First-year 6 20231
#> 351: MCID3112885339 20181 01 First-year 6 20233
data_sufficiency()
Add a column to a data frame of Student Unit Record (SUR) observations that labels each row for inclusion or exclusion based on data sufficiency near the upper and lower bounds of an institution’s data range.
Arguments.
dframeData frame of student-level records keyed by student ID. Required variables aremcidandtimely_term.midfield_tableData frame of student-level term observations keyed by student ID. Default isterm. Required variables aremcid,institution, andterm.
Equivalent usage. The following implementations yield identical results,
# Required arguments in order and explicitly named
x <- data_sufficiency(dframe = DT, midfield_table = term)
# Required arguments in order, but not named
y <- data_sufficiency(DT, term)
# Using the implicit default for the midfield_table argument
z <- data_sufficiency(DT)
# Demonstrate equivalence
check_equiv_frames(x, y)
#> [1] TRUE
check_equiv_frames(x, z)
#> [1] TRUEOutput. Adds the following columns to the data frame.
term_iStudent initial term, encoded YYYYT.lower_limitInitial term of an institution’s data range, encoded YYYYT.upper_limitFinal term of an institution’s data range, encoded YYYYT.data_sufficiencyLabel each observation for inclusion or exclusion based on data sufficiency: “include”, indicating that available data are sufficient for estimating timely degree completion; “exclude-upper”, indicating that data are insufficient at the upper limit of a data range; or “exclude-lower”, indicating that data are insufficient at the lower limit.
# Un-clutter the printout
DT <- DT[, .(mcid, term_i, timely_term)]
# Add data sufficiency column and supporting variables
DT <- data_sufficiency(DT, term)
DT
#> mcid term_i timely_term institution lower_limit upper_limit
#> <char> <char> <char> <char> <char> <char>
#> 1: MCID3111142225 19881 19933 Institution B 19881 20181
#> 2: MCID3111142283 19881 19933 Institution J 19881 20096
#> 3: MCID3111142290 19881 19933 Institution J 19881 20096
#> ---
#> 97553: MCID3112898894 20181 20233 Institution B 19881 20181
#> 97554: MCID3112898895 20181 20233 Institution B 19881 20181
#> 97555: MCID3112898940 20181 20233 Institution B 19881 20181
#> data_sufficiency
#> <char>
#> 1: exclude-lower
#> 2: exclude-lower
#> 3: exclude-lower
#> ---
#> 97553: exclude-upper
#> 97554: exclude-upper
#> 97555: exclude-upperSimilar to the details described in the previous section,
data_sufficiency() accepts Alternate source names and uses Silent overwriting when existing columns
have the same name as one of the added columns.
Closer look
The data range for the institutions are:
# Data range by institution
term[order(institution), .(min_term = min(term), max_term = max(term)), by = "institution"]
#> institution min_term max_term
#> <char> <char> <char>
#> 1: Institution B 19881 20181
#> 2: Institution C 19901 20154
#> 3: Institution J 19881 20096Example 3. Exemplifies “Student A” in Figure 1 or Figure 2. The student attends Institution C which has a data range of 1990–2015. The student’s initial term is Fall 2007 so the 1990 lower-limit exclusion does not apply; the student’s timely completion term is Spring 2013, so the 2015 upper-limit exclusion does not apply.
# Display one student by ID
DT[mcid == "MCID3112785480"]
#> mcid term_i timely_term institution lower_limit upper_limit
#> <char> <char> <char> <char> <char> <char>
#> 1: MCID3112785480 20071 20123 Institution C 19901 20154
#> data_sufficiency
#> <char>
#> 1: includeExample 4. Exemplifies “Student B” in Figure 1. The student attends Institution B which has a data range of 1988–2018. The student’s initial term is Spring 2013 so the 1988 lower-limit exclusion does not apply; the student’s timely completion term is Fall 2019, so the 2018 upper-limit exclusion does apply.
# Display one student by ID
DT[mcid == "MCID3111170322"]
#> mcid term_i timely_term institution lower_limit upper_limit
#> <char> <char> <char> <char> <char> <char>
#> 1: MCID3111170322 20133 20191 Institution B 19881 20181
#> data_sufficiency
#> <char>
#> 1: exclude-upperExample 5. Exemplifies “Student C” in Figure 2. The student attends Institution B which has a data range of 1988–2009. The student’s initial term is Fall 1988 so the 1988 lower-limit exclusion applies.
# Display one student by ID
DT[mcid == "MCID3112056754"]
#> mcid term_i timely_term institution lower_limit upper_limit
#> <char> <char> <char> <char> <char> <char>
#> 1: MCID3112056754 19881 19933 Institution J 19881 20096
#> data_sufficiency
#> <char>
#> 1: exclude-lower